As large language models (LLMs) scale up, researchers have begun to notice a growing imbalance between model size and the availability of high-quality training tokens.
The relationship between model parameters and training data volume is crucial:
models require increasingly more tokens to achieve optimal performance.
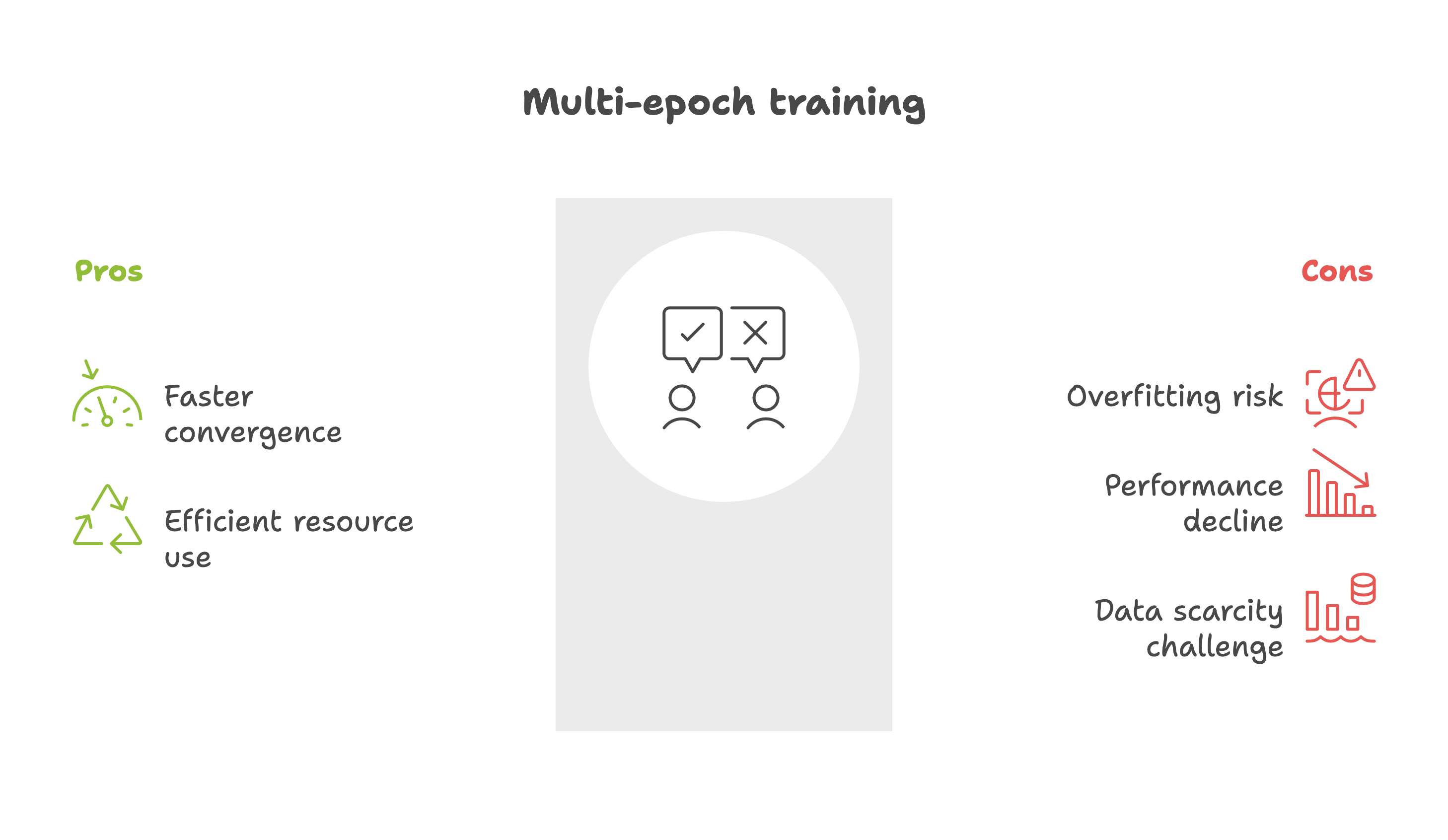
Past studies have given mixed answers. Hoffmann et al. (2022) found that repeated training on the same tokens degraded model performance.
Yet Taylor (Galactica, 2022) observed that up to four epochs improved performance.
To resolve these contradictions, researchers at the National University of Singapore (NUS) conducted a systematic study, analyzing how multi-epoch training affects LLM performance.
Repeated training on the same dataset hurts performance, both in pretraining and in downstream evaluations. While larger and higher-quality datasets alleviate this somewhat, they don’t eliminate the problem.
Given the limited availability of new data, future LLM development will likely face this token scarcity challenge.
Regularization techniques — especially dropout — can help, though they slow training.
In short:
Multi-epoch training on repeated data accelerates overfitting, and regularization is the key to mitigating (but not solving) it.